






Logging ist das einzige Thema dieser Serie, bei dem ich sicher bin, alle Entwickler schon konfron
tiert waren. Wir schreiben gerne Logs! In Dateien, in die Windows Event-Logs und in die Konsolenausgabe! Das hat bisher auch wunderbar funktioniert. Da wir nun aber eine Cloud-Native Applikation entwickeln wollen, sehen wir uns mit einigen Problemen konfrontiert:
- Logfiles gehen verloren wenn unsere Container neu starten
- Durch das Load-Balancing unseres Systems wissen wir nicht, wo wir Fehler suchen sollen
- Die schieren Mengen an Logs sind nicht mehr hilfreich
- Wo verschiedene Komponenten im Spiel sind, wissen wir nicht mehr wo die Fehler herkommen
All diese und viele weitere Probleme erwachsen aus der Tatsache, dass unsere Services nun skalieren und das System welche Sie skaliert dies vollkommen ohne unser Wissen oder Eingriffen tut. Container werden gestartet, gestoppt, auf andere Hosts verschoben und unsere Logs? Sie verschwinden in einem grossen schwarzen Loch. Stellen Sie sich vor, in einem System laufen mehrere hundert Instanzen eines Services. Ein Kunde meldet ein Problem beim Aufruf dieses Services. Die Aufgabe wäre nun, die Konsole jeder Instanz nach diesem Fehler zu durchsuchen! Das ist unmöglich. Das heisst also wir müssen einmal mehr Umdenken, denn das funktioniert nicht mehr:
Console.WriteLine("Failed to add record to database.");
Ein Fehler auf der Standard-Ausgabe ist also wenig hilfreich und belegt allerbestens ein bisschen Plattenspeicher bis der Container gestoppt wird – danach ist er komplett nutzlos! Ausserdem stellt sich nun die Frage, was denn wirklich schief gelaufen ist, dass der Datenbankzugriff nicht funktioniert hat? Netzwerkprobleme, Datenbank offline? Falsche Credentials? Aus diesem Log ist nichts ersichtlich!
Wir haben beim Logging drei Herausforderungen, welchen wir uns in der Cloud stellen müssen:
- Vergänglichkeit der Logs
- Verständlichkeit wiederherstellen
- Korrelations-Transparenz herstellen
Wie das möglich ist? Zum Beispiel so:
Schritt 1: Logs strukturieren
Den ersten Schritt den wir tun müssen, ist die Voraussetzung, damit wir unserem Logging-Problem überhaupt Herr werden. Wir hören auf, Logs als simple Zeichenfolgen zu behandeln! Tritt ein Fehler auf, müssen wir wissen warum. Wir müssen wissen, wie der Zustand des Systems zum Zeitpunkt des Fehlers war, damit wir den Fehler reproduzieren und beheben können. Das heisst, es braucht eine sinnvolle Fehlermeldung UND dazugehörigen strukturierte Daten, was dann so aussehen könnte:
log.Error("Failed to create user {username}: {reason}",
username,
excpetion.Message(),
userCreationRequest);
Mit unserem Fehler geht die Fehlernachricht und weitere Informationen wie die Struktur, welche alle Benutzerdaten enthält oder der gwünschte Username einher. Ebenfalls wichtig – dieser Log geht nicht in die Konsolenausgabe sondern in ein entsprechendes Log-Framework! Dieses kann den Fehler wahlweise auf die Konsole ausgeben, oder dann behandeln, wie im nächsten Abschnitt beschrieben wird!
Oft vergessen wir bei unseren Logs, dass es durchaus sinnvoll wäre, Loglevel zu benutzen. Loglevel wie Information, Debug, Warnings, Errors sind nicht da um Sie zu ignorieren oder nur unseren Lieblingsloglevel (Debug – natürlich…) zu verwenden! Wird etwas aus einen Request ignoriert, ist das Wert ein Warning auszugeben. Wird einem Feld ein Standardwert angenommen – weil es der Benutzer nicht gesetzt hat – ist ein Information-Log sinnvoll! Je mehr ich Loglevel bewusst einsetze umso sinnvoller und zielgerichteter wird mein Logging. Es wandelt sich von einer Debug-Hilfe zu einem wertvollen Werkzeug, welches mir Einblick in mein laufendes System verschafft und mir zeigt, wie Benutzer unser System einsetzen! Dieses Wissen ist unbezahlbar!
Schritt 2: Sammeln und Indexieren
Auch wenn wir ein Framework einsetzen um unsere Logs zu strukturieren, hilft uns dies wenig, wenn diese Logs jedesmal verloren gehen, wenn wir einen Container neu starten! Wir müssen die Logs also zentral sammeln und dort durchsuchbar machen. Wir könnten wir das tun? Nun wir könnten einen kleinen Service Entwicklern, welche unsere Logs in eine Datenbank schreibt. Die indexieren wir dann und können Sie so durchsuchen! Oder aber wir können aufhören wie Coder zu denken und uns überlegen ob wir wirklich die Ersten sind, welche Logs zentral sammeln müssen weil Sie ein verteiltes System entwickelt haben! Zu oft scheitern wir an unserer eigenen (in meiner Ansicht) arroganten Ansicht, dass wir bei jedem Problem, welches wir in der Praxis antreffen, die Ersten sind, welche dieses Problem je hatten! Die Antwort ist mit an Sicherheit grenzender Wahrscheinlichkeit: NEIN!
Ausserdem sind wir Entwickler etwas narzisstisch veranlagt sind: Wenn wir eine wunderbare Lösung auf ein Problem haben, können wir es nicht für uns behalten! Wir berieseln alle mit Ausführungen zu unserer One-To-Rule-Them-All-Lösung, welche auch nur ansatzweise die Bereitschaft zeigen uns zuzuhören! (Ich schliesse mich in diese Gruppe vollumfänglich mit ein!) Wir tun es an Konferenzen, in Blogs, in Podcasts und auf Youtube.
Was ich damit sagen will: Die Wahrscheinlichkeit ist hoch, dass es bereits einen Community-Talk zu genau meinem Problem gibt! Meist sogar ein Open-Source-Produkt zu genau meinem Problem, entwickelt auf die Kosten anderer – kostenlos zur Benutzung für mich. Das ist auch hier der Fall. Es gibt zahleiche Open-Source Projekte für Log-Aggregation und Tracing wie z.B OK-Log oder Logstash. OK-Log ist ein sehr einfach und gut administrier und skalierbares System. Logstash basiert auf ElasticSearch und ist daher im Umgang und Betrieb sehr komplex dafür aber sehr umfangreich und mit guter Sprachunterstützung!
Schritt 3: Korrelation wiederherstellen – Tracing
Verteilte Systeme haben es an sich, dass an einem Vorgang oft mehrere Komponenten beteiligt sind. Dabei können unterschiedliche Seiteneffekte entstehen. Komponenten können offline sein, oder ausgelastet und daher langsam antworten. Sie können Fehler produzieren und wir müssen wissen wo Fehler herkommen und Sie beheben zu können! Hier kommt ein etwas unbekannteres Konzept ins Spiel: Tracing. Dabei geht es darum, Logs und Fehler in einen Kontext zu bringen. Wir möchten sehen, welche Services angesprochen werden, wenn ein Request auf unserer API eintrifft, sehen wo sich unsere Performance-Bottlenecks befinden! Tracing soll es für uns richten.
Auch in diesem Fall sind wir keine einzigartigen Schneeflocken! Es gibt sogar Industriestandards wie OpenTracing, welche wir uns zu Nutze machen können. Im OpenTracing-Ökosystem existieren viele wunderbare Werkzeuge wie z.B. Jaeger, welches ursprünglich von Uber stammt und nun von der Cloud-Native-Foundation entwickelt wird. Tracing-Frameworks für unterschiedlichste Sprachen und Plattformen stehen zur Verfügung und viele standardisierte Services bieten bereits die Möglichkeit einer Open-Tracing-Integration! Die Jaeger-Komponenten ermöglichen es nicht nur, den Verlauf eines Requests visuell zu rekonstruieren, sondern auch Log-Nachrichten mit diesem Verlauf zusammenzuführen! Das Rundum-Sorglos-Packet für Logging und Tracing könnte dann so aussehen:
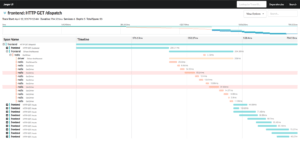
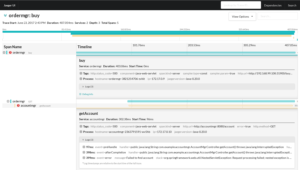
Logs können von einem Problem zu einem Asset werden. Sie können uns nicht nur helfen Fehler schnell zu finden, sondern auch Information aus den Tiefen unserer Systeme zur Tage fördern, welche uns helfen können Optimierungen an unseren Schnittstellen zu machen oder Flaschenhälse zu finden! Dafür müssen wir Logs strukturieren, sammeln und in Kontext setzen, ein paar OS-Projekte einsetzen – Erledigt! Einfach, nicht?
Dieser Artikel ist Teil der Cloud-Native Serie:
- Intro: Das Ding mit den Cloud-Native Apps
- Entwickler-Kultur
- Architektur
- Logging & Tracing
- Metriken


