




Metriken: Unsere Infrastruktur Admins kennen sie schon lange – wir Softwareenwickler fragen uns noch, ob wir Sie wirklich brauchen. In Cloud-Native Applikationen ist Schluss mit Fragen: Im ersten Teil dieser Blog-Serie haben wir festgehalten, dass die Ansprüche unserer Nutzer gestiegen sind. Lange Wartezeiten oder gar Downtime sind keine Option mehr. Unsere Desktop-Apps konnten wir noch an unseren Benutzern testen, welche uns dann etwas frustriert unsere langsamen Datenbankabfragen aufzeigten. Davon müssen wir uns lösen. Wenn Usern unserer Web-Apps ein Performance-Problem melden, müssten wir als Entwickler dies eigentlich schon lange vorher bemerkt haben! Wie geht das? Wo müssen wir anfangen?
Metriken
Metriken machen den Zustand unseres Systeme sichtbar. Sie sind Datenpunkte welche von unterschiedlichen Systemen erzeugt und dann zentral gesammelt werden. Metriken können unterschiedliche Formen annehmen:
- Counter: Summen diskreter Werte wie z.B. Anzahl aktiver Nodes im Netzwerk oder Restarts von Containern.
- Histogramme: Zeitfolgen für Werte
- Gauges: Werte welche inkrementiert und dekrementiert werden
Stakeholder
Nicht alle Metriken sind für alle Zielgruppen unseres Systems interessant:
- Infrastructure Engineers: Sie stellen unsere Infrastruktur bereit. Werden also Netzwerke unzuverlässig oder Disks voll laufen möchten sie das wissen uns Abhilfe schaffen!
- Operations Engineers: Wenn Applikation unter Last kommen, müssen Sie diese entsprechend Skalieren können. Wenn grosse Kunden neu auf die Infrastruktur zugreifen brauchen wir Anhaltpunkte, wie viel zusätzliche Ressourcen bei der Infrastruktur benötigt werden!
- Software Engineers: Wie stark wachsen unsere Datenbanken? Gibt es Abfragen, welche konstant langsamer werden? Wie entwickelt sich die gefühlte Performance für den Benutzer?
Metriken werden für entsprechende Interessengruppen erfasst! Deren Interessenbereiche können sich durchaus auch überlappen! Es gibt jedoch drei Bereich in welche sich Metriken auf Grund Ihrer Herkunft einteilen lassen:
- Infrastruktur Metriken: kommen aus unserer Infrastruktur, das kann ein Public-Cloud-Provider wie Azure sein, oder aber unser Virtualisierungssystem wie z.B VmWare. Möglich Datenpunkte sind: Memory-Auslastung des Clusters, Total verfügbare vs. Benutzte Ressourcen (Compute, Memory, Storage, IP Adressen etc.), Up-Times jeder VM oder Crashes…
- System Metriken: kommen aus dem Betriebssystem und bieten detaillierten Einblick in die Ressourcen-Verwaltung innerhalb einer Maschine, welche uns das Virtualisierungssystem nicht bieten kann. Mögliche Metriken hier sind: Anzahl laufender Prozesse, Ressourcen-Benutzung pro Prozess (Compute, Memory, Storage, Network, etc.), Write-Read-Raten auf den Disks gesamt und pro Prozess, Cache-Grössen etc.
- Applikations Metriken: kommen direkt aus unseren Applikationen, geben Einblick in einen laufenden Prozess und sind besonders für uns als Entwickler interessant da wir genau auf diese Faktoren den grössten Einfluss haben! Interessante Datenpunkte könnten sein: Request Rates, Error/Status Rates, Request/Response Body-Grössen, Requests pro Rest-Endpunkt, Requests pro Mandant, Durchschnittliche Abfragezeiten pro DB-Abfrage, oder Latenz beim Zugriff auf externe APIs etc. Es liegt in unseren Händen, ob und welche Metriken wir in unseren Applikationen erfassen!
Metriken == Information
Metriken sind Informationen – davon können wir nie genug haben! Was heute für uns nicht interessant ist – kann unter einem DDOS Angriff bereits Morgen überlebenswichtig sein! Es gilt also der Grundsatz: Keine Metrik ist nutzlos, sie ist bestenfalls unbenutzt! Doch wie werden Metriken benutzt?
Sammeln
Das Sammeln von Metriken geschieht meist automatisiert und fortlaufend. Dieser fortlaufende Prozess ermöglicht es uns einen sehr zeitnahen Einblick in die Auslastung unserer Systeme und einzelnen Komponenten. Das Sammeln von Infrastrukturmetriken muss stark von unserer Hosting-Infrastruktur unterstützt werden. Dies ist in Public-Clouds sehr gut gewährleistet, in On-Premise Infrastruktur können oft Daten von Systemen wie V-Sphere, Hyper-V etc. ausgelesen und aufbereitet werden.
Systemmetriken können über verschiedenste Werkzeuge gesammelt werden. Tools wie z.B. Telegraf exportieren eine Vielzahl von Systemrelevanten Metrikpunkte wie z.B. welche Prozesse wieviel und welche Ressourcen belegen. Während für Systemmetriken sehr gute Standard-Tools bestehen, ist das Sammeln von Applikationsmetriken uns Entwicklern auferlegt. Sehr wohl bestehen auch hier gute Bibliotheken – doch müssen wir uns bereits während dem Bau unserer Systeme damit auseinandersetzen. Denn ist die Software im produktiven Einsatz können wir nicht einfach ein Tool nebenher laufen lassen, welches unsere Applikationsmetriken mit magischer Hand erscheinen lässt!
Besonders interessante Applikationsmetriken können Datenbank-Zugriffe sein. Deren Dauer, Latenz, Reponse-Sizes können sehr gute Frühwarn-Informationen sein. Ist z.B ein einer Abfrage eine stetig steigende Abfragedauer zu beobachten, ist hier eine Optimierung der Abfrage abgebracht. Wir können dies jedoch frühzeitig erkennen bevor sich ein ernsthaftes Problem bemerkbar macht.
Da beim Sammeln von Metriken kontinuierlich grosse Datenmengen gesammeln werden, ist das Zusammentragen der Daten nicht so einfach. Viele Metriksysteme setzen dabei ein eine zweistufigen Prozess: Erst werden Daten, welche in einem laufenden Prozess gesammelt wurden dort grob aggregiert (z.B das Berechnen von fortlaufenden Durchschnitten). Danach werden diese einem Collector (Sammler) übermittelt oder von diesem aktiv abgeholt. Dieser bündelt Datensätze und übermittelt diese Bündel an ein spezielles Storage-System. Traditionelle ER-Datenbanken sind nicht gut dafür geeignet, fortlaufende Datensatze (Metriken werden auch oft als Time-Series bezeichnet) zu verwalten und bedingen oft duch Ihre ACID-Garantien einen zu tiefen Durchsatz sowohl mein Schreiben, als auch beim Indexieren und Abfragen der Daten. Zum Speichern und Abfragen von Time-Series eignen sich Systeme wie z.B:
- TICK Stack (umfangreiche Komplettlösung zum Sammeln, Bündeln, Aggregieren, Speichern und Visualisieren von Daten)
- Logstash & Elastic Search (Mächtiges verteiltes System zum Indexieren, Aggregieren und Abfragen grosser Datenmengen)
Visualisieren
Metriken zu visualisieren bedeutet haufenweise Daten Sinn zu geben:
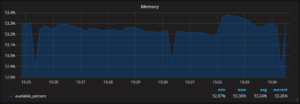
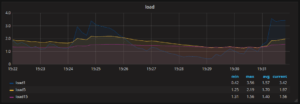
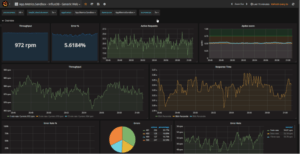
Es gibt eine breite Auswahl an Dashboarding-Tools auf dem Markt, mit welchen Metriken aus verschiedensten Quellen visualisiert werden können. Hier spielt es nicht wirklich eine grosse Rolle welches Dashboard wir einsetzen, so lange wir die von unseren Applikationen und System gesammelten Metriken sinnvoll aufbereiten, grafisch darstellen und auswerten können.
Einige Vertreter der Dashboarding-Familie sind z.B.:
Nicht auf die eine oder andere Art virtualisierte Metriken sind nutzlose Datenhaufen – und teuer! Daher sollten wir uns diese Daten so weit wie nur möglich zu Nutzen machen! Viele Log-Stacks bieten auch die eine oder andere Möglichkeit so etwas wie eine Notfallbenachrichtigung über verschiedenste Medien einzurichten, wenn Metrik-Daten aus dem Ruder laufen sollten. Dies ermöglicht uns eine unschlagbar tiefe Reaktionszeit auf Vorfälle in unseren Systemen, welche unsere SLA mit den Kunden beeinflussen.
Unsere Reaktion auf Service-Unterbrüche wird von unseren Kunden sehr Kritisch bewertet – mit einem umfangreichen Satz an Metriken können wir schneller, zielgerichteter und kompetenter auf die unausweichlich kommenden Ausfälle reagieren und so das Vertrauen unserer Kunden gewinnen.
Dieser Artikel ist Teil der Cloud-Native Serie:


