



Apache Kafka ist eine verteilte Open Source Streaming Plattform, mit welcher Messages ausgetauscht und Events gespeichert werden können. In meinem ersten Blogpost zu Kafka habe ich die generellen Vor- und Nachteile der Technologie beschrieben. Nun möchte ich auf konkrete Beispiele eingehen, wie Kafka bei uns in der Leuchter IT Solutions AG verwendet wird und was potenzielle andere Einsatzszenarien sind.
Die Verwendung von Apache Kafka muss, wie bei jeder anderen einzusetzende Technologie, von Applikation zu Applikation einzeln beurteilt werden. Einer der grössten Indikatoren für oder gegen den Entscheid von Kafka hängt von den jeweiligen Use Cases ab, die in der Applikation abgebildet werden sollen. Robert C. Martin verwendet in seinem Buch «Clean Architecture» den Begriff «Screaming Architecture». Er beschreibt mit dem Ausdruck, dass der grundlegende Aufbau einer Applikation auf der höchsten Betrachtungsebene nicht nach Frameworks schreien soll, sondern nach der jeweiligen Domäne, in welcher die Applikation verwendet wird. Der Artikel kann auch auf Uncle Bobs Blog nachgelesen werden. Ähnlich wie die Architektur einer Applikation nach «Banksystem» oder «Gesundheitssystem» schreien soll, müssen nun auch die Use Cases der neuen Software nach «Kafka» schreien, um dessen Einsatz zu legitimieren. Denn der Betrieb und die Wartung von Kafka bringt einen nicht zu vernachlässigen Mehraufwand und Komplexität mit sich, welche es sorgsam abzuwägen gilt. In den folgenden Absätzen gehe ich auf zwei Beispiele ein, in welchen sich der Einsatz gelohnt hat.
Schnell und einfach skalierbar
Als erstes Beispiel konnten wir mit Kafka in einer Kundenapplikation folgenden Use Case abbilden: Unternehmen mussten Daten im XML-Format an eine unserer Applikationen schicken, welche anschliessend validiert und gespeichert wurden. Die Validierung und Speicherung waren dabei nicht zeitkritisch, der Import dieser Daten jedoch schon. Je nach Grösse der Unternehmen waren die gesendeten Dateien sehr gross und beinhalteten hunderttausende von Einträgen. Um die Rohdaten effizient und schnell entgegen zu nehmen, nutzen wir die enorme Schnelligkeit von Kafka, welche mit Millionen von Messages pro Sekunde umgehen kann. Dadurch konnten wir Kafka als eine Art Cache nutzen, in welchem alle Daten für zwei Wochen gespeichert wurden. Für die anschliessende Validierung konnte eine weitere Stärke von Kafka genutzt werden: die einfache Skalierung. Um die riesige Menge an Daten zu verarbeiten und in unser System einzupflegen, konnten nach Bedarf einfach und unkompliziert mehrere Consumer alloziert werden. So wurden Peaks bei hoher Last einfach gebrochen. Zusammenfassend in zwei Wörtern waren die Gründe für die Verwendung von Kafka also Geschwindigkeit und Skalierung.
Folgende Grafik zeigt eine Übersicht der involvierten Parteien:
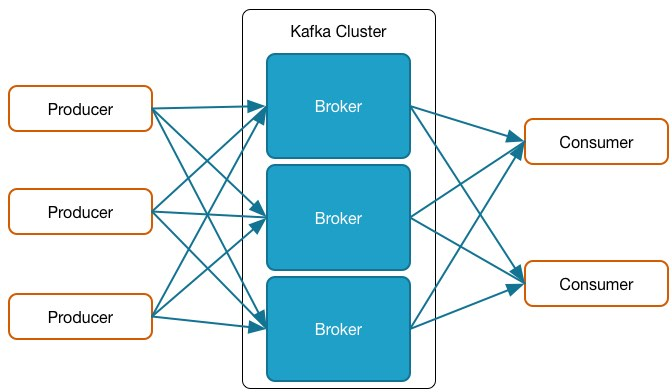
Die Producer sind in meinem Beispiel die Lieferanten von Daten, welche in kurzer Zeit eine grosse Menge davon an unsere App schickte. Die einzelnen Kafka Broker speicherten diese als Events. Schlussendlich konnten flexibel Consumer alloziert werden, um die Daten zu validieren und importieren.
Event-Sourcing und Message-Bus
Das zweite Beispiel findet sich in der eigenentwickelten SaaS-Lösung Docugate Web: Aufgrund der Event-Sourcing-Architektur der Applikation dient Kafka zum einen als klassischer Event-Store, in welchem alle Events persistiert werden. Er agiert dabei zuverlässig und mit all seinen Vorteilen bezüglich Geschwindigkeit und Verfügbarkeit. Zum anderen dient Kafka auch als Message-Bus, mit welchem die unterschiedlichen Microservices Nachrichten austauschen können. Für beide Probleme gäbe es natürlich auch andere Lösungen, welche das gleiche oder gar bessere Resultat liefern können. So könnte bspw. als Message-Bus auch ActiveMQ oder RabbitMQ genutzt werden, welche je nach Vorwissen des DevOps-Teams im produktiven Betrieb einfacher zu warten sind und genau dasselbe Resultat liefern. Da Kafka gleichzeitig als Event-Store und Message-Bus dienen kann und das interne Knowhow für diese Technologie bei uns vorhanden ist, fiel der Entscheid aber schlussendlich auf Kafka.
Nach was schreit Ihre Applikation?
Mit den beschriebenen Beispielen nutzten wir alle Core-Fähigkeiten von Kafka: Hoher Durchsatz, Skalierbarkeit, persistenter Speicher sowie Hochverfügbarkeit und wurden damit nicht enttäuscht. Die Entscheidung, ob und wie Kafka genutzt werden soll, hängt massgebend von den Problemen ab, welche man damit lösen möchte. Zwar bringt Kafka eine gewisse Komplexität in eine Applikation, es liefert hingegen aber auch den entsprechenden Benefit, welche den Aufwand mehr als wettmacht. Für viele Datenverwaltungssysteme mit simplen CRUD-Operationen würde dieser zusätzliche Aufwand den Nutzen bei weitem übersteigen und Kafka nur einzusetzen, weil es bekannte Firmen wie Adidas, Netflix oder Spotify auch tun, ist definitiv der falsche Ansatz. Zudem erfordert der produktive Betrieb von Kafka ein entsprechendes Knowhow, welches entweder durch Selbststudium oder durch qualifizierte bestehende oder neue Mitarbeiter erworben werden muss. Beide Wege sind aufwendig bzw. teuer und könnten situativ auch einfach durch simplere Messaging-Systeme gelöst werden. Es lohnt sich deshalb, für jede Applikation sorgfältig auf die abzubildenden Prozesse zu achten und darauf, nach was sie schreien. Gerne unterstützen wir Sie dabei hinzuhören, was Ihre Applikation genau braucht und zu helfen, die richtige Entscheidung zu treffen.
Haben Sie Fragen zu Apache Kafka, Streaming & Messaging Plattformen oder Microservices und Event Sourcing? Wir helfen Ihnen gerne weiter!
Hinterlassen Sie einen Kommentar oder kontaktieren Sie uns für ein unverbindliches Beratungsgespräch:


