




In einer aussergewöhnlichen Lage wie der leider immer noch aktuellen Pandemie ist Kommunikation besonders wichtig. Die bewährten «einfachen» Formen verwenden wir jeden Tag. Sei es das synchrone Telefongespräch mit den Arbeitskollegen im Homeoffice oder die asynchrone Nachricht in die WhatsApp-Chatgruppe der Familie, um nachzufragen, wie die Stimmung ist. Jedes Mitglied der Gruppe erhält die Nachricht unabhängig voneinander und kann selbst entscheiden, ob und wann sie oder er antwortet.
Wie geht nun jedoch der Bund vor, der allen Bürgerinnen und Bürgern der Schweiz wichtige Informationen zustellen muss? Der Bund kann schlecht jeden Haushalt anrufen und die Nachricht überbringen, denn das wäre viel zu langsam, zu teuer und zudem hat nicht jeder ein Telefon. Er kann auch keine Nachricht via WhatsApp verschicken, da er nicht sicherstellen kann, dass alle diese Nachricht bekommen und auch lesen. Die Lösung des Problems liegt im Delegieren der Aufgabe. Es werden allseits bekannte Medien wie bspw. die nationalen Radio- und Fernsehsender verwendet, welche die Nachrichten immer und immer wieder senden. Alle Bürgerinnen und Bürger, welche Zugang zu diesen Medien haben, können diese Kanäle abonnieren und sich so die Informationen automatisch zusenden lassen.
Miteinander sprechen – aber wie?
Vor ähnlichen Herausforderungen in der Kommunikation stehen wir in der Entwicklung von Microservice-Architekturen, welche in jüngster Zeit eine Renaissance erleben. Es werden Systeme entwickelt, die aus mehreren einzelnen kleinen Software-Einheiten, sogenannten Microservices, bestehen. Die einzelnen Einheiten kennen sich im besten Fall untereinander nicht und wissen schon gar nicht, dass es weitere Services gibt. Jede Komponente dient ihrem Zweck und erfüllt diesen eigenständig. Aber wie übermittle ich nun Resultate oder Nachrichten an Komponenten, von welchen ich nicht weiss, wo sie sind und dass es sie überhaupt gibt? Die Lösung in unserem Fall heisst nicht SRF3 oder 20 Minuten, sondern Apache Kafka.
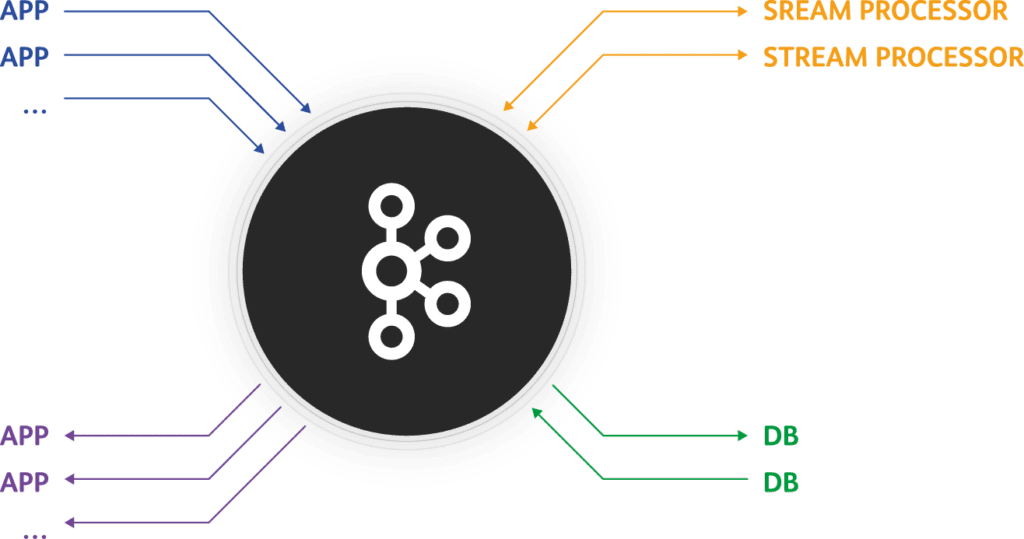
Bei Kafka handelt es sich um eine Streaming Plattform, welche für das Verteilen und Bearbeiten von grossen Mengen an Daten konzipiert wurde. Kafka kann dabei in einer Cloud-Umgebung verteilt installiert werden, ist fehlertolerant und schnell. Sehr schnell! Wie aber kann uns Kafka nun mit unserem Kommunikationsproblem helfen? Dafür gibt es konkret zwei Einsatzmöglichkeiten.
Möglichkeit 1: Kafka als Message Broker
Kafka kann als traditioneller Message Broker eingesetzt werden. Dabei verhält sich Kafka als zentrale Anlaufstelle und fungiert als Vermittler von Nachrichten. Das Prinzip ist dabei das klassische Publish und Subscribe Pattern. Microservices können sich auf sogenannte Topics registrieren, für welche sie sich interessieren. Produzenten von Nachrichten schicken nun ihre Nachricht, welche sie verbreiten möchten, an Kafka. Bspw. hat der Client-Service einen neuen Benutzer erstellt. Kafka stellt nun sicher, dass jeder Teilnehmer, welcher sich für diese Nachricht interessiert, diese auch zugestellt bekommt. Die Lebenszeit einer Nachricht kann dabei konfiguriert werden. So wird diese zum Beispiel nach dem erfolgreichen Zustellen an alle Konsumenten gelöscht oder erst nach einer definierten Zeitspanne.
Möglichkeit 2: Event Sourcing mit Kafka
Im beschriebenen Szenario können traditionelle Messaging Systeme wie ActiveMQ oder RabbitMQ ohne Weiteres mithalten und sind gleich zu verwenden wie Kafka. Für was die beiden erwähnten Produkte jedoch nicht zu verwenden sind und wo Kafka erst richtig brillieren kann, ist Event Sourcing. Bei Event Sourcing handelt es sich um ein architektonisches Konzept, bei welchem jede Zustandsänderung in der Applikation gespeichert wird. Im traditionellen Ansatz in einer Applikation mit einer relationalen Datenbank werden Zustände von Objekten gespeichert. Zum Beispiel wird meine Bestellung in einem Onlinehandel als shipped gespeichert und wechselt den Zustand auf delivered, sobald der Postbote auf seinem Gerät die Bestellung als zugestellt visiert.
In einem Event Sourcing getriebenen System würde nun nicht der Zustand gespeichert, sondern die ausgeführten Events. Um beim erwähnten Beispiel zu bleiben: die Events also, welche von den jeweiligen Services publiziert werden. Der Zustand dieser Bestellung kann somit nicht direkt in einer Datenbank gelesen werden, sondern wird aufgrund der generierten Events reproduziert. Das bringt insbesondere den Vorteil, dass jede Änderung nachvollzogen werden kann, was in einer relationalen Datenbank nicht immer ganz so einfach ist. Ein weiter Vorteil ist, dass alle Events zu jedem Zeitpunkt immer wieder gelesen werden können. Ein Analyse-Service, welcher erst zu einem späteren Zeitpunkt erstellt wurde, kann so alle je generierten Events zu Bestellungen lesen und bspw. analysieren, wieso Toilettenpapier nach Ausbruch der Pandemie so gefragt war.
Datenbanken in Applikationen können sehr schnell vom Gigabyte- in den Terabyte-Bereich anwachsen. Wenn man diese Grössen auf einzelne Events herunterrechnet, muss das entsprechende System, in dem die Events gespeichert werden, mit mehreren 100 Millionen von Event-Daten umgehen können. Genau für dieses Szenario ist Kafka ausgelegt. Kafka bleibt gleich performant, egal ob man nur wenige Kilobyte oder bereits Terabyte an Event-Daten gespeichert hat. Aufgrund der Tatsache, dass Kafka auf mehrere Server verteilt und als Cluster eingesetzt werden kann, bleibt die Performanz gewährleistet. Schreib- und Lesezugriffe der Events können so effizient aufgeteilt werden und aufgrund der Replizierung aller Events auf mehreren Partitionen in Kafka gehen auch keine Events verloren.
Aus alt mach neu
Kafka bietet noch viel mehr als die zwei beschriebenen Fälle. Vielfach haben Unternehmen moderne Applikationen und alte Legacy Systeme im Einsatz. Die neuere Umgebung basiert auf Event Sourcing und das alte System ist ein klassischer Monolith mit einer grossen SQL-Datenbank als Speicher. Da die beiden Systeme dennoch miteinander sprechen müssen oder zumindest Daten aus beiden Applikationen verarbeitet werden sollen, bietet Kafka Connect die passende Lösung. So können Daten vom alten System in der neueren Umgebung verwendet werden und bei Bedarf wieder zurück in das Legacy System geschrieben werden.
Je nach Ziel und Grösse einer neuen Applikation kann Kafka die ideale Lösung sein. Sei es in einer komplett neuen Systemlandschaft oder in Kombination mit Legacy Code.
Haben Sie Fragen oder brauchen neue Ideen für Ihre IT-Umgebung? Wir helfen Ihnen gerne weiter. Hinterlassen Sie hier einen Kommentar oder kontaktieren Sie uns für ein unverbindliches Beratungsgespräch:


